
5 Marzo 2025
Webhero è di nuovo Google Premier Partner 2025: un riconoscimento d’eccellenza nel digital marketingLeggi tutto
"Internet Archive è una immensa biblioteca online che memorizza siti web, libri e file. Scopri come funziona e a cosa serve.
Devi sapere che, contrariamente a quello che si crede, non proprio tutto si può trovare sui motori di ricerca. Molti siti con il tempo vengono cancellati e con il tempo vengono rimossi dagli indici dei motori di ricerca. Ci vorrebbe una specie di maxi biblioteca digitale dove conservare i siti e i file che altrimenti andrebbero perduti. Qualcosa come Internet Archive!
Internet Archive è un archivio contenente tutti i siti ormai desueti e non più esistenti
Internet Archive o Archive.org svolge il ruolo di enorme biblioteca online no-profit con il compito di preservare l’esistenza di libri digitali, video, film, canzoni, immagini e interi siti web provenienti da ogni parte del mondo. Ogni giorno milioni di navigatori fanno uso di questo sito, uno dei 300 più visitati al mondo, che dal 1996 salva copie dei contenuti online e li mette gratuitamente a disposizione di tutti.
Dietro l’Archive.org (che è un altro nome di questa poderosa biblioteca virtuale) vi è una vera e propria organizzazione i cui uffici amministrativi sono stanziati a San Francisco.
Lo scopo di questa organizzazione è di preservare la conoscenza sotto ogni sua forma, un po’ come le biblioteche, solo che in questo caso è rivolto a ogni genere di contenuto, dai libri ai film, dalla musica ai software.
Archive.org si basa sulla Wayback Machine, una applicazione introdotta nel 2001 che si occupa di memorizzare automaticamente le scansioni dei siti web e di renderle disponibili all’interno del portale come dei “fermi immagine”.
Le pagine sono salvate sui server di Archive.org che li restituiscono proprio come erano al momento della scansione, anche se da allora sono passati anni.
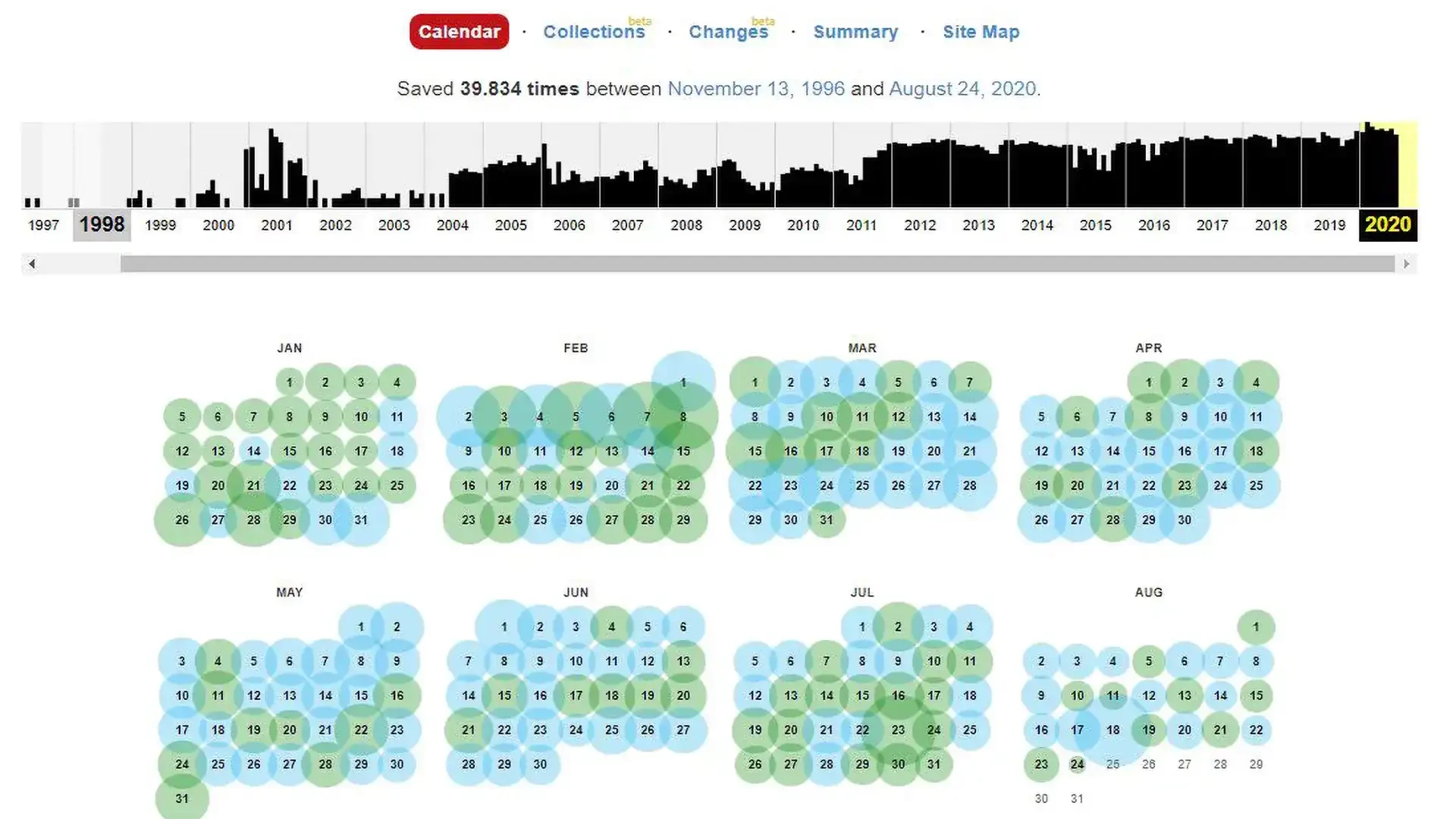
I siti web vengono registrati come fossero delle fotografie, e questo anche nel caso di siti dinamici che vengono “congelati” e memorizzati con quelle attuali caratteristiche, compresi i link al loro interno. La schermata ci mette a disposizione dei “calendari” dai quali possiamo selezionare la versione del sito che vogliamo esplorare: ad esempio potremmo entrare in quella del 5 maggio 2015 oppure del 10 settembre 2019. Ogni “scan” del sito viene archiviata in occasione di una precisa data e ora rendendo molto facile scegliere la versione che ci interessa.
Archive.org contiene 14 miliardi di contenuti testuali, 35 miliardi di materiali di altro genere, qualcosa come 400 miliardi e agisce da “copia di backup” dei contenuti dell’intero web dal 1996 a oggi. Si tratta di un immenso database contenente opere multimediali provenienti dai quattro angoli del globo, un aiuto immenso per preservare la memoria storica dei siti web e della cultura in generale.
Le opere contenute in ordine cronologico possono essere sfogliate come repliche dei siti in un dato periodo. All’interno dei server della poderosa piattaforma sono salvate infatti varie copie di ogni sito web corrispondenti a diversi periodi temporali.
Certo, non possiamo essere sicuri che ogni elemento di ogni sito al mondo sia presente e completo al 100%: file grafici o allegati potrebbero non essere disponibili. La navigazione inoltre potrebbe essere non intuitiva e il caricamento abbastanza lento.
Rispetto comunque all’enorme mole di contenuti che mette a disposizione gratuitamente, si tratta di un ben misero limite!
Fai una prova con un sito che conosci e che sai essere scomparso da anni: probabilmente è lì dentro, pronto a essere consultato!
La Wayback Machine indicizza i siti che possono essere visualizzati dai motori di ricerca, ma permette anche di scansionare appositamente dei siti per includerli nei suoi archivi. La piattaforma provvede periodicamente ad analizzare il sito in questione per includere nei propri archivi delle versioni successive dello stesso portale.
Possiamo accedere quindi a una cronologia lunga anni a cui possiamo accedere per visionare le versioni dei vari siti in diversi momenti della storia. Nel sito troviamo un apposito form di ricerca nel quale possiamo digitare la parola chiave che ci interessa e consultare tutti i siti che ci vengono restituiti per esso.
In Archive.org possiamo trovare molti contenuti come:
Si stima che al suo interno vi siano 11 milioni di testi, 1 milione di immagini, oltre 100.000 software. I contenuti del sito sono divisi in diverse collezioni come le community legate ai file audio, video, testuali, biblioteche americane, università ecc. che rende ancora più facile orientarsi.
Il sito comprende innumerevoli elementi come film d’epoca e antichi libri per i quali il copyright è decaduto. La sezione dei video ad esempio contempla innumerevoli esami di arte visiva come cortometraggi ai tempi di guerra, film d’epoca, programmi televisivi storici, che senza questo portale sarebbero molto difficilmente rintracciabili.
La categoria delle immagini ci mette a disposizione illustrazioni liberamente utilizzabili con licenza Creative Commons oppure di pubblico dominio. Possiamo trovare ad esempio collezioni di foto e di illustrazioni messe a disposizione da università e biblioteche di tutto il mondo e che possono essere utilizzate liberamente.
Wayback Machine cataloga e include materiali sul web in maniera automatica. Comunque, un sito dall’indicizzazione inibita tramite robots.txt non può essere incluso dalla Wayback Machine. Se i siti vengono contrassegnati con il noindex, diventano non indicizzabili in maniera retroattiva e vengono esclusi dall’archiviazione nella Wayback Machine.
Wayback Machine è una piattaforma eccellente per studiare l’evoluzione di un sito web nel corso del tempo, oltre che per ritrovare copie di materiali multimediali che altrimenti finirebbero perdute nel dimenticatoio.
Si tratta di un sito formidabile per tutti coloro che ad esempio vogliono ritrovare video e giochi ormai irrecuperabili, film d’epoca introvabili, contenuti di siti web ai quali si era affezionati, e per gli studiosi che vogliono vedere come un sito è cambiato nel corso del tempo.
All’interno di Archive.org possiamo consultare gli elementi distinti nelle categorie Libri, Audio, Video, e ogni classificazione comprende altre sotto-distinzioni. Possiamo eseguire delle ricerche su specifici argomenti come programmi TV, contenuti testuali, siti web.
L’archivio dei siti web si trova su http://web.archive.org/
Immettiamo il dominio del sito Web nella pagina principale nel campo di ricerca. Nel nostro caso sarà Repubblica.it
Dopo aver inserito il collegamento al sito web, vediamo il calendario di salvataggio del codice html della pagina. In questo calendario, vediamo le note in diversi colori sulle date di salvataggio
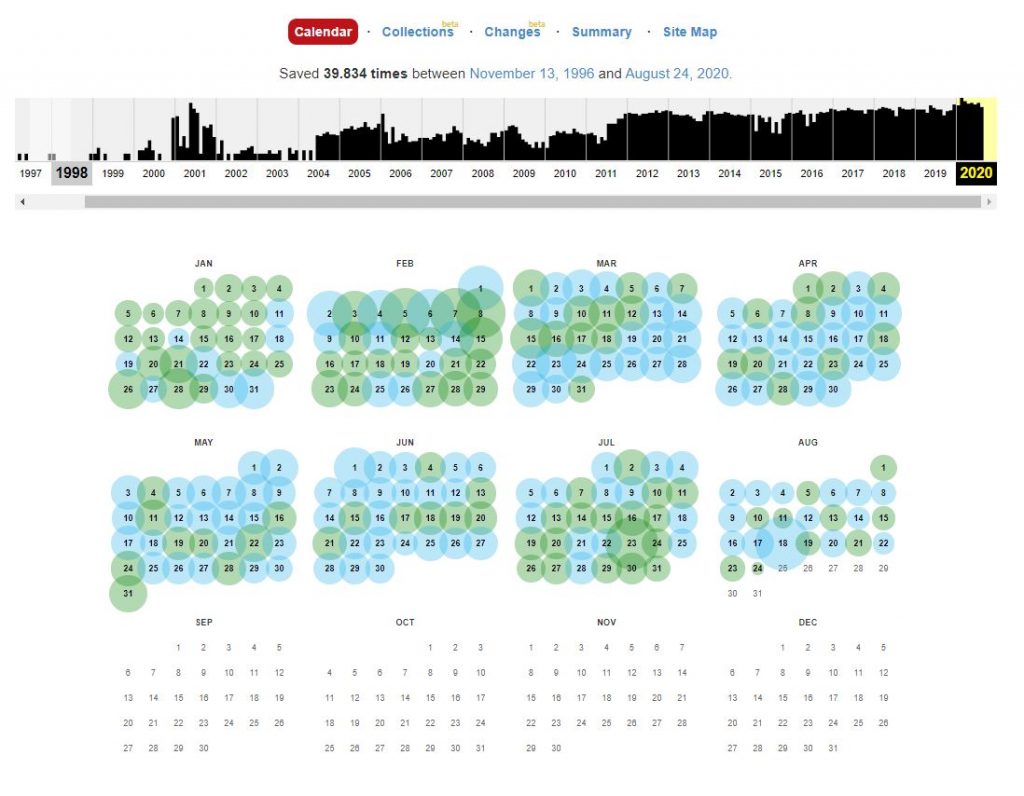
Blu significa risposta del codice 200 valida del server (nessun errore dal server);
Il rosso (può essere giallo o arancione, a seconda del browser e del sistema operativo del PC) significa errore 404 o 403, qualcosa che non è interessante durante il ripristino. Il verde sta per reindirizzamento delle pagine (301 e 302).
I colori del calendario non danno una garanzia di conformità al 100%: nella data blu è possibile anche un reindirizzamento (non a livello di intestazione, ma, ad esempio, nel codice html della pagina stessa: nei meta tag di aggiornamento (schermata aggiorna i tag) o in JavaScript).
Ora prendiamo una data a caso tipo l’8 novembre del 2001 e vedremo la bella pagina di Repubblica di quel giorno. Sembra passato un secolo eh?

E tu che cosa ne pensi di questa biblioteca online? L’hai già utilizzata o pensi di farlo? Parliamone qua sotto!

Leggi tutto

Ho rinvenuto internet archive per caso, molto interessante.!
proverò ad utilizzare questo strumento